Planning is hard. If you overestimate your ability to beforehand know details of the future, your planning will fail. Even if you only plan for a two week iteration. Like Harry Callahan said in Magnum Force, ?a man’s got to know his limitations?.
Problem
This article is based on the Scrum Process Template, since I think it is the most popular one.
If used right, TFS is a great tool for planning project work. Unfortunately it is fairly common that its planning capabilities are used in a counterproductive way which can make TFS hard to work with.
- If lots of PBIs are added to the backlog it makes it hard to get an overview. For example to know which PBIs needs more attention before they can be started to work on, one need to categorize them somehow. Some do it by a parent-child relationship between PBIs, but then it hard to prioritize between PBIs belonging to different parents since TFS orders the backlog by their respective parents.
- People tend to focus on the Iteration Backlog which makes it easy to forget about the more important large scoped workflows. It is common that the team focus on micro managing stuff that really does not matter, like task beak down and estimation. It is not uncommon to find PBIs with more than ten tasks added to them.
- Most tasks are added during the planning meeting, but almost always some are added during the sprint to cover for details which was not initially thought of. Some call this scope creep, but it should really be called bad planning.
Discussion
When planning, a primary concern should be making PBIs that are small enough so that they can be delivered when the sprint is over. The larger a PBI gets, the higher the risk that it does not reach ?done? (whatever that means for your team) at the end of the sprint. Half-finished PBIs need to be split which is not only a time consuming activity in itself, but is also bad for accuracy of the Velocity key metric.
Your coworkers depend on the state of the PBI and not the state of its tasks. For example, a test specialist might be interested in PBIs that are ready to be tested. A developer specialist wanting to start working on a PBI might be interested in when a dependent upon PBI is implemented. If the team hangs around in the Sprint Backlog these states are not visual enough, nor are they easy to update.
If the team backlog is a mix of PBIs that are ready to work on, and some are not, it is hard to know what items to handle during a grooming meeting. The result in the long run can be a backlog full of junk which is prioritized in an order that cannot be trusted.
Why using tasks might be a bad idea
If you are used of adding tasks to a PBI you might feel that it is not that important to fill in the Description field. When the description field is empty you will most likely forget about the Acceptance Criteria as well.
One can question the tradeoff from using tasks in your team. Is it really that important for you to check in code against a task? Are your burndown charts that precious that you must have them? Especially if they do not even slope downward, as often is the case.
If you do not have tasks, you are forced to do a better job creating the PBIs. For example, they automatically get smaller and with more detailed information. Project stakeholders will be happy. And as a nice bonus for yourself, you are no longer asked to estimate bogus hours on tasks. When was the last time that it played out as you thought? Everybody wins!
Well, using tasks might be a good idea for some. Maybe your project has very few dependencies, your team is experienced and you know very well what has to be done. But still, the first step for everyone should be to get familiar with PBIs and how they should be used. Then after you think you have mastered their creation and workflow activities, go ahead and use tasks.
How to use TFS to keep a clean backlog
It is a bad idea to keep your planning of future sprints in the team backlogs.
One might be tempted to do the planning in another tool, but that is not optimal either. It is always best to keep all related information in the same place. TFS actually comes with the possibility to have different backlogs for different teams, which solves this problem.
In a project consisting of two teams, one might use the following configuration:
Teams
- Root Team, can access both team backlogs
- PO Team, planning of future PBIs
- Team 1
- Team 2
Area configuration
- Future, default for PO Team
- Team, default for Root Team
- 1, default for Team 1
- 2, default for Team 2
Planning for the future and grooming activities are performed in the PO team, which results in clean backlogs for the other two teams. Most of the time, they will only contain items from the current sprint. This makes the Backlog Items Board usable in the iteration. The combined status of the teams can be examined through the Root Team backlog.
Customizing Kanban Columns
PBIs and Bugs comes with two types of states. The normal New-Approved-Committed-Done state, and a customizable Kanban state. The latter can be thought of like a sub-state of the normal state. It can unfortunately not be shared across teams, but is an easy way to customize the workflow within a team. The Kanban states are represented by columns in the Backlog Items Board.
To illustrate what is possible, I have taken screen shots from the respective team backlogs of my example. These can be customized without changing the Scrum Process Template, which means that it does not matter if you run an On Premise TFS installation or in the cloud service Visual Studio Online.
The PO Team Backlog
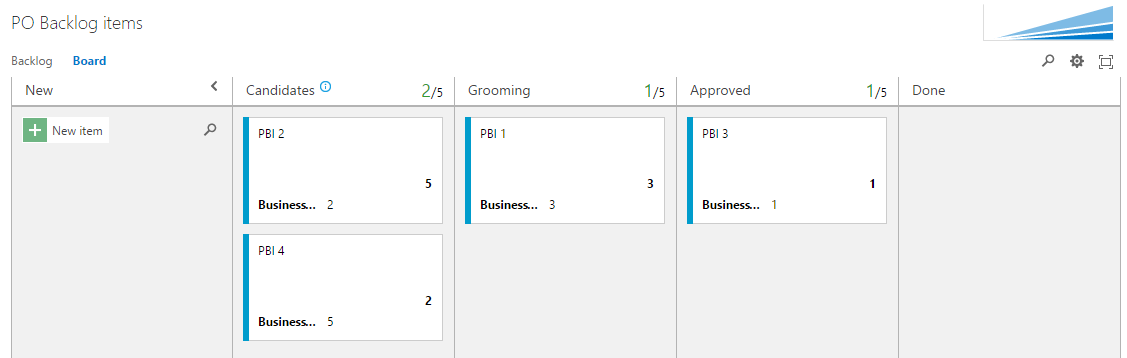
The PO Team is responsible for creating new PBIs, which are given the new state by default. The Kanban columns Candidates and Grooming are added as sub-states of New. When a PBI is detailed enough so that work can be started it is moved to the Approved column which sets the Approved state. The PBI will not show up in a team backlog until it is moved to the area path of a team.
Note that the Business Value field is added in the cards because it gives great meaning for the PO Team.
The Team 1 Backlog
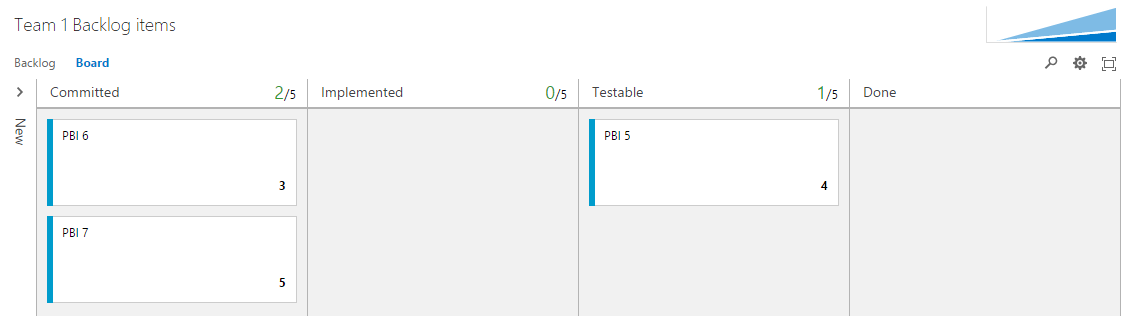
The Team 1 and 2 are responsible for implementing approved PBIs from the PO Team. PBIs which are committed to during a sprint is moved to the Committed state. The Approved state is not shown in the Board since sprint planning is normally done in the Backlog- and not in the Board view.
The Kanban columns Implemented and Testable are added as sub-states of Commited. When tests are passed PBIs are moved to the Done column which sets the Done state.
The Team 2 Backlog
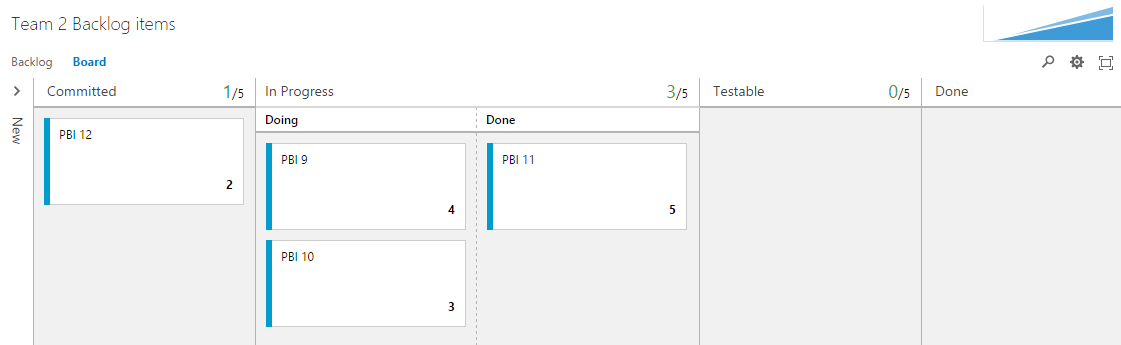
Here the Kanban columns In Process and Testable are added as sub-states of Committed. In Process use the Split Column functionality.
The Root Team Backlog
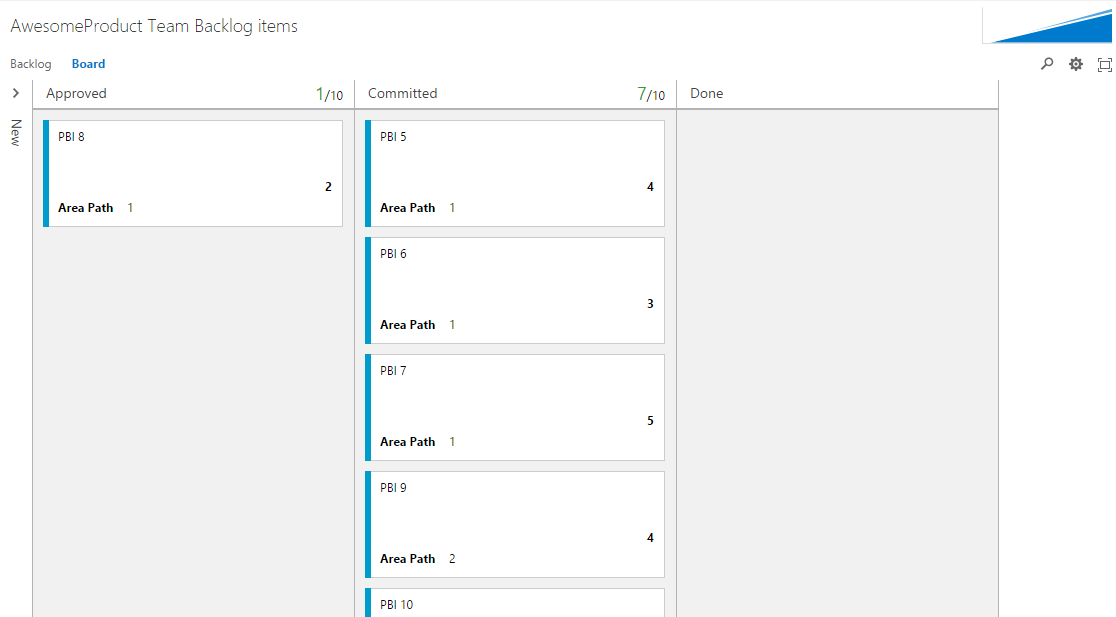
The Root Team is not used to do any real work but only view the combined backlogs of Team 1 and 2. Since Kanban states are not shared cross teams there is no use adding any extra columns to the board.
Because work items are included from different teams it gives meaning to display the area path on the cards.
Using Excel to Move PBIs between Areas
A nice feature of TFS is that you can edit work items through Excel. In short it gets a list of work items from a Query and lets you edit them all in a spreadsheet instead of doing it one by one. It also lets you create new work items or change parent-child relations.
To use this feature you have to have Excel (obviously) and Visual Studio installed. You can read in the instructions on MSDN that it is sufficient to install Team Explorer if you do not already have Visual Studio installed, although I have never tried that for myself.
To get started simply open Excel, under Team ribbon click New List, Select your Query and you are good to go. When you are done editing press Publish to upload your changes to TFS.
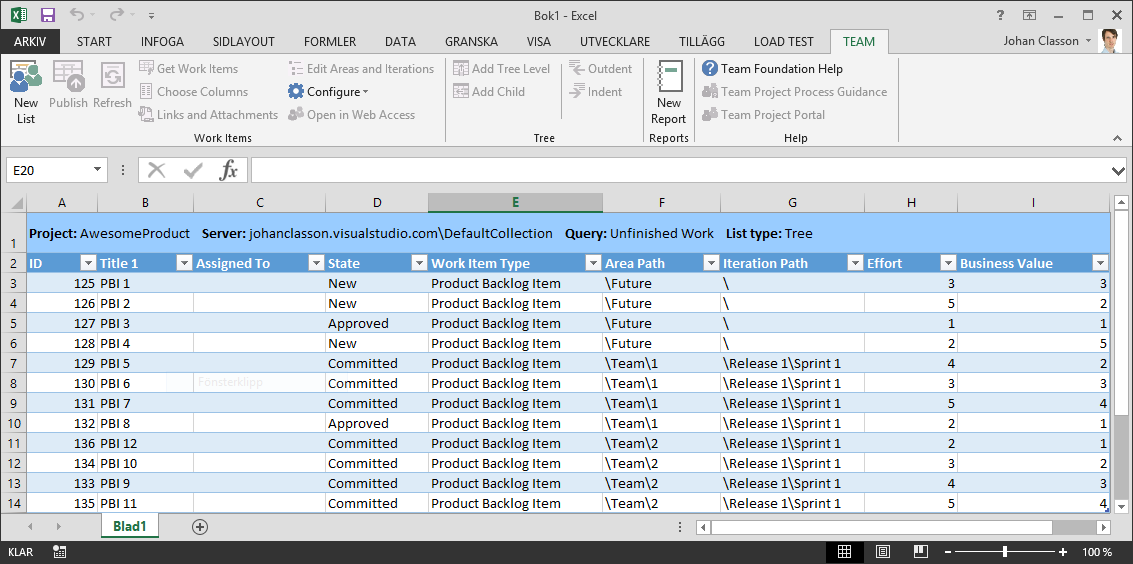
Using the TFS spreadsheet functionality is the most convenient way to move approved PBIs from the PO Team to one of backlogs of Team 1 or 2.
Note that there are intentionally no iterations in my example. I did not check any iterations because I would like to help (or force if you are fond of strong words) the teams to keep their PBIs in order.
Happy planning!