The process that suites your team best might be different from what might be best for someone else. In this blog post, I would like to share how you can construct release notes with Azure DevOps in a nice ordered fashion.
When you need to publish release notes you might be facing difficulties such as:
- How to make them awesome (!).
- How to reach your audience.
- How to be as effective as possible.
TL;DR;
1) Write release notes in Product Backlog Items (PBIs).
2) Collect release notes from PBIs into a Markdown document.
3) Review by pull request (PR).
4) Publish.
Making Them Awesome
What Changes Have Been Introduced Since Last Release?
Obviously, you need some way to find out which changes that have been made, and also, which of those that are candidates to be included in the release notes.
Just prior to the release, you could construct a list of all changes manually, for example by summarizing the pushed commits. This approach is optimal if your team works in an ad-hoc fashion or without planning.
If you really want to, you can diff what code that changed since last release, and then write the release notes with that as guidance.
You might be tempted to use a Git repository log as reference, be aware of that commit messages might not be the best source of information for release notes since they are often written for other developers! If developers are indeed your target audience, you could just as well direct them to your repository instead of summarizing its log in a document somewhere.
My point here is that I do not recommend you relying on a tool for summarizing your release notes. By just planning a little you will have your summary already. For example, if you decide beforehand what to include in a release, then you will already have a nice list of what to include in the release notes.
What Changes Might Be of Importance to the Audience, and What Changes Might Not?
In Azure DevOps I plan my releases with PBI work items. I have found it convenient to include a custom boolean field in the PBI that I can then use for making a query to select just the right PBIs to include in the release notes.
If you have different audiences, you can consider adding multiple boolean fields, one for each audience.
How to add custom fields to work items are described in the official Azure DevOps documentation.
How Can You Make Sure That the Information in the Release Notes Are Correct?
In my opinion, the ones best qualified to describe a change is probably the ones that have implemented it. This means that I do not think that it is a good idea to let just a few people write the release notes. Instead you should have your whole team engaged in writing them.
You might think that this is overkill, but in the best of worlds, I think that you would benefit from writing the release notes for a PBI before you start implementing it. The idea is to force you to think about the end-user or customer’s perspective as early as possible in your development process.
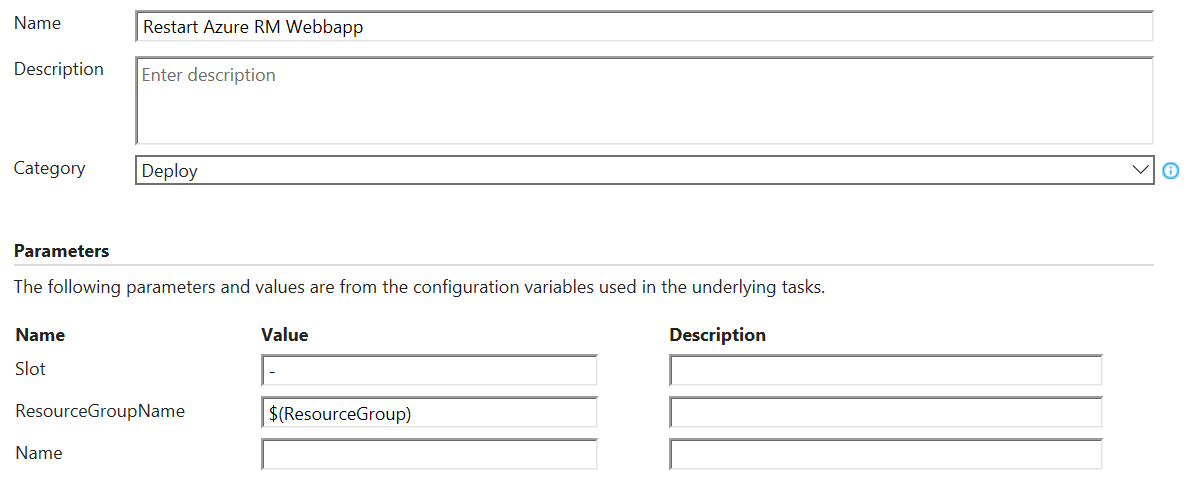
I recommend that you include custom text-fields for release notes directly in the PBI. That way it will be easy to find where to write. Here is an example.
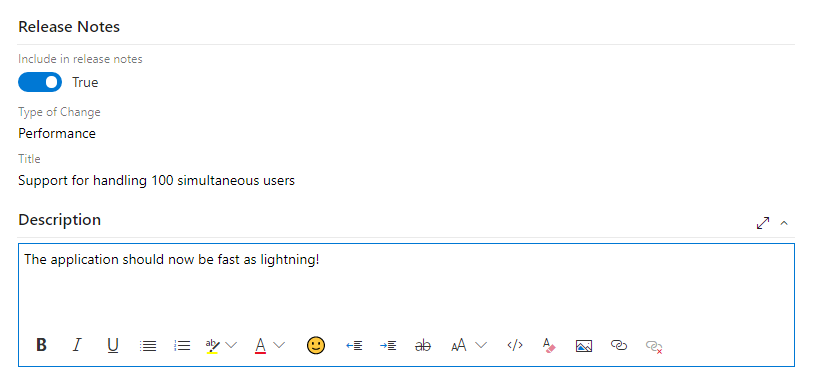
If your team do not commit to writing release notes beforehand, you could add a reminder for everyone to finish their release notes by including it in your team’s definition of done.
How to Make the Release Notes Readable?
Of course you can make a best effort writing nice readable descriptions for each PBI. I imagine this is a matter of personal opinion, but I think it is hard to make proof-reeding when I only have the release notes from a single PBI on the screen. Therefore, I like to collect all release notes from the PBIs into a single document before the review process begins.
I treat that single document as the final product, and hence I often do not care to update the descriptions in the PBIs. These can be seen upon as just history if you will.
You can find an example how to generate release notes in Markdown format using PowerShell in this gist. The script iterates all work items returned by a query and constructs the document content from the custom title- and description-fields in those.
Here is an example of how to use it:
1 | $content = .\Get-ReleaseNotes.ps1 -Pat 'abc123' -Organization 'Fabrikam' -Project 'Fiber' -Query 'My Queries/Release Notes' |
My format of choice for release notes is Markdown, and that is because of the following reasons.
- Markdown is a perfect format for making reviews through PRs to a Git repository.
- It is relatively easy to convert Markdown into whatever format you need to publish in.
I would like to stress that the more people that are engaged in both writing and reviewing release notes the better they become. In addition to involving technical experts in the review process, I also like to have generally skilled writers review the document at least once before it is published.
How to Reach Your Audience
Difference audiences a best reached by different means. For example, if you do not have direct contact with your end users you might want to publish your release notes as HTML on your product’s website. Or if your audience does not actively search for release notes you might want to consider publishing your release notes as a PDF-file which you mail to your end users.
If you would like to be fancy, you can integrate the release notes into the actual product so that your end users can pull up-, or are presented with-, the release notes just as they use the new version of your product the first time.
How to Be as Effective as Possible
Doing all of this planning, PBI-tinkering and reviewing might seem like a lot of work. But I hope that you might soon realize that it is indeed less work compared to manually construct release notes in an ad-hoc fashion.
Also, when you write the release notes close to when you design or implement a change, then you do not have to spend as much time figuring out what to write.
I think that being effective is not only about spending less time writing release notes, but also that you also produce content with high quality. The review process is essential to archive this. Please do not skip reviewing of your release notes!
If your teams are already familiar with doing PRs to review code, reviewing release notes in the same way should not be so complicated.
Process
Here I will summarize an example of how the overall process might look like.
The release notes owner manages a work item query which selects the work items which are meant to be included in the release notes.
An overview of the process around creating release notes is presented below.
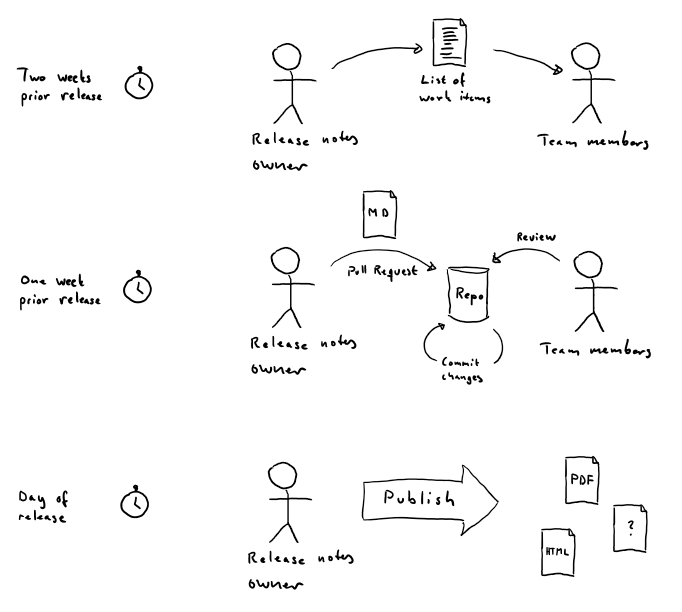
Two Weeks Prior Release
The release notes owner executes the query and mails its result to the team members who can see if some work items are missing or should be removed.
One Week Prior Release
When everyone has completed entering the release notes in the selected work items, the release notes owner generates a Markdown-file and starts a pull request. The team reviews the document, correcting mistakes until everyone agrees that the quality is high enough at which point the pull request is merged.
Day of Release
The release notes owner triggers an automated process which converts the Markdown-file to various possible formats.